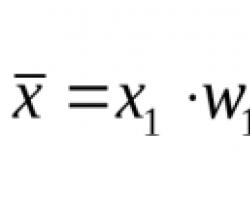Для выборки можно определить ряд числовых характеристик, которые аналогичны основным числовым характеристикам случайных величин в теории вероятностей (математическое ожидание, дисперсия, среднее квадратическое отклонение, мода, медиана) и являются в некотором смысле (который будет ясен дальше) их приближенным значением.
Пусть дано статистическое распределение выборки объема n для частот и относительных частот:
|
x i |
x 1 |
x 2 |
x k |
|
|
n i |
n 1 |
n 2 |
n k |
|
x i |
x 1 |
x 2 |
x k |
|
|
w i |
w 1 |
w 2 |
w k |
Если внести множитель под знак суммы, то получим формулу для выборочного среднего через относительные частоты:
 .
.
Отметим,
что в случае интервального ряда выборочное
среднее вычисляется по тем же формулам,
если в качестве чисел х
1
,
… , х
k
взять
середины интервалов:  ,
… ,
,
… , .
.
Выборочной дисперсией называется среднее арифметическое квадратов отклонений значений выборки от их выборочного среднего:
Снова внося множитель под знак суммы, получим формулу для выборочной дисперсии через относительные частоты:
Несложные преобразования приводят к более удобной формуле для вычисления выборочной дисперсии
 ,
,
где есть выборочное среднее квадрата изучаемой случайной величины, т.е.
Если
выборка представлена интервальным
статистическим рядом, то формулы для
выборочной дисперсии остаются те ми
же, где, как обычно, в качестве чисел х
1
,
… , х
k
берутся
середины интервалов:  ,
… ,
,
… , .
.
Выборочным средним квадратическим отклонением называется квадратный корень из выборочной дисперсии
![]() .
.
Размахом вариации R называется разность между максимальным и минимальным значением в выборке. Если варианты в выборке ранжированы (размещены в возрастающем порядке), то
![]() .
.
Коэффициент вариации определяется по формуле
 .
.
Модой М о вариационного ряда называется вариант, имеющий наибольшую частоту (или относительную частоту).
Медианой М е вариационного ряда называется число, являющееся его серединой. Для дискретного ряда с нечетным числом вариант медиана равна его серединному варианту. Если же число вариант четно, то Медина равна среднему (т.е. полусумме) двух серединных вариант.
К основным статистическим характеристикам ряда измерений (вариационного ряда) относятся характеристики положения(средние характеристики, или центральная тенденция выборки); характеристики рассеяния(вариации, или колеблемости) и характеристики формыраспределения.
К характеристикам положения относятся среднее арифметическое значение (среднее значение), мода и медиана.
К характеристикам рассеяния (вариации, или колеблемости) относятся: размах вариации, дисперсия, среднее квадратическое (стандартное) отклонение, ошибка средней арифметической (ошибка средней), коэффициент вариации и др.
К характеристикам формы относятся коэффициент асимметрии, мера скошенности и эксцесс.
Оценка параметров генеральной совокупности
Существуют точечные и интервальные оценки генеральных параметров.
Точечной одним числом . К таким оценкам относятся, например,

Для того чтобы статистические оценки давали «хорошие» приближения оцениваемых параметров, они должны быть:
несмещенными;
эффективными;
состоятельными.
Оценка называется несмещенной, если математическое ожидание ее выборочного распределения совпадает со значением генерального параметра.
Точечная оценка называется эффективной, если она имеет наименьшую дисперсию выборочного распределения по сравнению с другими аналогичными оценками, т.е. обнаруживает наименьшую случайную вариацию.
Точечная оценка называется состоятельной, если при увеличении объема выборочной совокупности она стремиться к величине генерального параметра.
Например, выборочная средняя есть состоятельная, несмещённая оценка генеральной средней. Для выборки из нормальной генеральной совокупности эта оценка является также и эффективной.
При выборке малого объема точечная оценка может значительно отличаться от оцениваемого параметра, т.е. приводить к грубым ошибкам. По этой причине при небольшом объеме выборки следует пользоваться интервальными оценками.
Интервальной называют оценку, которая определяется двумя числами – концами интервала – доверительного интервала .
Интервальные оценки позволяют установить точность и надежность оценок.
Для оценки генерального параметра с помощью доверительного интервала необходимы три величины:
Например,
доверительный интервал для генеральной
средней находится
по формуле:при
уровне значимости![]() .
.
Доверительный интервал - термин, используемый в математической статистике при интервальной оценке статистических параметров, более предпочтительной при небольшом объёме выборки, чем точечная.
Уровень значимости - это вероятность того, что мы сочли различия существенными, а они на самом деле случайны.
Когда мы указываем, что различия достоверны на 5%-ом уровне значимости, или при р < 0,05 , то мы имеем виду, что вероятность того, что они все-таки недостоверны, составляет 0,05.
Когда мы указываем, что различия достоверны на 1%-ом уровне значимости, или при р < 0,01 , то мы имеем в виду, что вероятность того, что они все-таки недостоверны, составляет 0,01.
Если перевести все это на более формализованный язык, то уровень значимости - это вероятность отклонения нулевой гипотезы, в то время как она верна.
Ошибка, состоящая в той, что мы отклонили нулевую гипотезу, в то время как она верна, называется ошибкой 1 рода. (См. Табл. 1)
 Табл.
1. Нулевая и альтернативные гипотезы и
возможные состояния проверки.
Табл.
1. Нулевая и альтернативные гипотезы и
возможные состояния проверки.
Вероятность такой ошибки обычно обозначается как α. В сущности, мы должны были бы указывать в скобках не р< 0,05 или р< 0,01, а α< 0,05 или α< 0,01.
Если вероятность ошибки - это α , то вероятность правильного решения: 1-α. Чем меньше α, тем больше вероятность правильного решения.
Исторически сложилось так, что в психологии принято считать низшим уровнем статистической значимости 5%-ый уровень (р≤0,05): достаточным – 1%-ый уровень (р≤0,01) и высшим 0,1%-ый уровень (р≤0,001), поэтому в таблицах критических значений обычно приводятся значения критериев, соответствующих уровням статистической значимости р≤0,05 и р≤0,01, иногда - р≤0,001. Для некоторых критериев в таблицах указан точный уровень значимости их разных эмпирических значений. Например, для φ*=1,56 р=О,06.
До тех пор, однако, пока уровень статистической значимости не достигнет р=0,05, мы еще не имеем права отклонить нулевую гипотезу. Мы будем придерживаться следующего правила отклонения гипотезы об отсутствии различий (Но) и принятия гипотезы о статистической достоверности различий (Н 1).
Для математико-статистического анализа результатов выборки знать только характеристики положения недостаточно. Одна и та же величина среднего значения может характеризовать совершенно различные выборки.
Поэтому кроме них в статистике рассматривают также характеристики рассеяния (вариации, или колеблемости ) результатов .
Определение. Размахом вариации называется разница между наибольшим и наименьшим результатами выборки, обозначается R и определяется
R =X max - X min .
Информативность этого показателя невелика, хотя при малых объёмах выборки по размаху легко оценить разницу между лучшим и худшим результатами спортсменов.
Определение. Дисперсией называется средний квадрат отклонения значений признака от среднего арифметического.
Для несгруппированных данных дисперсия определяется по формуле
где
Х
i
– значение признака,
 -
среднее арифметическое.
-
среднее арифметическое.
Для данных, сгруппированных в интервалы, дисперсия определяется по формуле
 ,
,
где х i – среднее значение i интервала группировки, n i – частоты интервалов.
Для упрощения расчётов и во избежание погрешностей вычисления при округлении результатов (особенно при увеличении объёма выборки) используются также другие формулы для определения дисперсии. Если среднее арифметическое уже вычислено, то для несгруппированных данных используется следующая формула:
2
= ,
,
для сгруппированных данных:
 .
.
Эти формулы получаются из предыдущих раскрытием квадрата разности под знаком суммы.
В тех случаях, когда среднее арифметическое и дисперсия вычисляются одновременно, используются формулы:
для несгруппированных данных:
2
= ,
,
для сгруппированных данных:
 .
.
3. Среднее квадратическое (стандартное ) отклонение
Определение. Среднее квадратическое (стандартное ) отклонение характеризует степень отклонения результатов от среднего значения в абсолютных единицах, т. к. в отличие от дисперсии имеет те же единицы измерения, что и результаты измерения. Иначе говоря, стандартное отклонение показывает плотность распределения результатов в группе около среднего значения, или однородность группы.
Для несгруппированных данных стандартное отклонение можно определить по формулам
= ,
,
= или
=
или
= .
.
Для данных, сгруппированных в интервалы, стандартное отклонение определяется по формулам:
 ,
,
 или
или
 .
.
Ошибка средней арифметической характеризует колеблемость средней и вычисляется по формуле:
 .
.
Как видно из формулы, с увеличением объёма выборки ошибка средней уменьшается пропорционально корню квадратному из объёма выборки.
Коэффициент вариации определяется как отношение среднего квадратического отклонения к среднему арифметическому, выраженное в процентах:
 .
.
Считается, что если коэффициент вариации не превышает 10 %, то выборку можно считать однородной, то есть полученной из одной генеральной совокупности.
ЭФФЕКТИВНАЯ ПОВЕРХНОСТЬ (ПЛОЩАДЬ) РАССЕЯНИЯ - характеристика отражающей способности цели, выражаемая отношением мощности эл. магн. энергии, отражаемой целью в направлении приёмника, к поверхностной плотности потока энергии, падающей на цель. Зависит от… … Энциклопедия РВСН
Квантовая механика … Википедия
- (ЭПР) характеристика отражающей способности цели, облучаемой электромагнитными волнами. Значение ЭПР определяется как отношение потока (мощности) электромагнитной энергии, отражаемой целью в направлении радиоэлектронного средства (РЭС), к… … Морской словарь
полоса рассеяния - Статистическая характеристика экспериментальных данных, отражающая их отклонение от средних значения. Тематики металлургия в целом EN desperal band … Справочник технического переводчика
- (функция передачи модуляции), ф ция, с помощью к рой оценивают «резкостные» св ва изображающих оптич. систем и отд. элементов таких систем. Ч. к. х. есть преобразование Фурье т. н. функции рассеяния линии, описывающей характер «расплывания»… … Физическая энциклопедия
Функция передачи модуляции, функция, с помощью которой оценивают «резкостные» свойства изображающих оптических систем и отдельных элементов таких систем (см., например, Резкость фотографического изображения). Ч. к. х. есть Фурье… …
полоса рассеяния - статистическая характеристика экспериментальных данных, отражающая их отклонение от среднего значения. Смотри также: Полоса полоса скольжения полоса сброса полоса прокаливаемости … Энциклопедический словарь по металлургии
ПОЛОСА РАССЕЯНИЯ - статистическая характеристика экспериментальных данных, отражающая их отклонение от средних значения … Металлургический словарь
Характеристика рассеяния значений случайной величины. М. т. h связана с квадратичным отклонением (См. Квадратичное отклонение) σ формулой Этот способ измерения рассеяния объясняется тем, что в случае нормального… … Большая советская энциклопедия
ВАРИАЦИОННАЯ СТАТИСТИКА - ВАРИАЦИОННАЯ СТАТИСТИКА, термин, объединяющий группу приемов статистического анализа, применяющихся преимущественно в естественных науках. Во второй половине XIX в. Кетле (Quetelet, «Anthro pometrie ou mesure des differentes facultes de 1… … Большая медицинская энциклопедия
Математическое ожидание - (Population mean) Математическое ожидание – это распределение вероятностей случайной величины Математическое ожидание, определение, математическое ожидание дискретной и непрерывной случайных величин, выборочное, условное матожидание, расчет,… … Энциклопедия инвестора
Главная характеристика рассеивания вариационного ряда называется дисперсией
Главная характеристика рассеивания вариационного ряда называется дисперсией . Выборочная дисперсия D в рассчитывается по следующей формуле:
где x i – i -ая величина из выборки, встречающаяся m i раз; n – объём выборки; – выборочная средняя; k – количество различных значений в выборке. В рассматриваемом примере: x 1 =72, m 1 =50; x 2 =85, m 2 =44; x 3 =69, m 3 =61; n =155; k =3; . Тогда:
Заметим, что чем больше значение дисперсии, тем сильнее отличие значений измеряемой величины друг от друга. Если в выборке все значения измеряемой величины равны между собой, то дисперсия такой выборки равна нулю.
Дисперсия обладает особыми свойствами.
Свойство 1. Значение дисперсии любой выборки неотрицательно, т.е. .
Свойство 2. Если измеряемая величина постоянна X=c, то дисперсия для такой величины равна нулю: D [ c ]= 0.
Свойство 3. Если все значения измеряемой величины x в выборке увеличить в c раз, то дисперсия данной выборки увеличится в c 2 раз: D [ cx ]= c 2 D [ x ], где c = const .
Иногда вместо дисперсии используют выборочное среднее квадратическое отклонение , которое равно арифметическому квадратному корню из выборочной дисперсии: .
Для рассмотренного примера выборочное
среднее квадратическое отклонение равно ![]() .
.
Дисперсия позволяет оценить не только степень различия измеряемых показателей внутри одной группы, но может быть использована и для определения отклонения данных между разными группами. Для этого используется несколько видов дисперсии.
Если в качестве выборки берётся какая-либо группа, то дисперсия данной группы называется групповой дисперсией . Чтобы выразить численно различия между дисперсиями нескольких групп, существует понятие межгрупповой дисперсии . Межгрупповой дисперсией называется дисперсия групповых средних относительно общей средней:

где k – число групп в общей выборке, - выборочная средняя для i -ой группы, n i – объём выборки i -ой группы, - выборочная средняя для всех групп.
Рассмотрим пример.
Средняя оценка за контрольную работу по математике в 10 «А» классе составила 3.64, а в 10 «Б» классе 3.52. В 10 «А» учится 22 человека, а в 10 «Б» - 21. Найдём межгрупповую дисперсию.
В данной задаче выборка разбивается на две группы (два класса). Выборочная средняя для всех групп равна:
 .
.
В таком случае межгрупповая дисперсия равна:
Поскольку межгрупповая дисперсия близка к нулю, то мы можем сделать вывод, что оценки одной группы (10 «А» класса) в малой степени отличаются от оценок второй группы (10 «Б» класса). Иными словами, с точки зрения межгрупповой дисперсии рассмотренные группы в незначительной степени отличаются по заданному признаку.
Если общая выборка (например, класс учеников) разбита на несколько групп, то помимо межгрупповой дисперсии можно рассчитать ещё внутригрупповую дисперсию . Такая дисперсия является средней величиной для всех групповых дисперсий.
Внутригрупповая дисперсия D внгр рассчитывается по формуле:

где k – количество групп в общей выборке, D i – дисперсия i -ой группы объёма n i .
Существует взаимосвязь между общей (D в ), внутригрупповой (D внгр ) и межгрупповой (D межгр ) дисперсиями:
D в = D внгр + D межгр .
| Одна из причин проведения статистического анализа заключается в необходимости учитывать влияние на исследуемый показатель случайных факторов (возмущений), которые приводят к разбросу (рассеянию) данных. Решение задач, в которых присутствует разброс данных, связано с риском, поскольку даже при использовании всей доступной информации нельзя точно предугадать, что же произойдет в будущем. Для адекватной работы в таких ситуациях целесообразно понимать природу риска и уметь определять степень рассеяния набора данных. Существуют три числовые характеристики, описывающие меру рассеяния: стандартное отклонение, размах и коэффициент вариации (изменчивости). В отличие от типических показателей (среднее, медиана, мода), характеризующих центр, характеристики рассеяния показывают, насколько близко к этому центру располагаются отдельные значения набора данных | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Определение стандартного отклонения | Стандартное отклонение (среднее квадратическое отклонение) является мерой случайных отклонений значений данных от среднего. В реальной жизни большинство данных характеризуется рассеянием, т.е. отдельные значения располагаются на некотором расстоянии от среднего. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Использовать стандартное отклонение как обобщающую характеристику рассеяния, просто усреднив отклонения данных нельзя, потому что часть отклонений окажется положительной, а другая часть – отрицательной, и, вследствие этого, результат усреднения может оказаться равным нулю.
Чтобы избавиться от отрицательного знака, применяют стандартный прием:
сначала вычисляют дисперсию
как сумму квадратов отклонений, поделенную на (n
–1), а затем из полученного значения извлекают квадратный корень.
Формула для вычисления стандартного отклонения выглядит следующим образом:
Замечание 1. Дисперсия не несет никакой дополнительной информации по сравнению со стандартным отклонением, однако ее сложнее интерпретировать, т. к. она выражается в «единицах в квадрате», в то время как стандартное отклонение выражено в привычных для нас единицах (например, в долларах).
Замечание 2. Приведенная выше формула предназначена для расчета стандартного отклонения по выборке и более точно называется выборочное стандартное отклонение
.
При расчете стандартного отклонения генеральной совокупности
(обозначается символом s) производят деление на n
.
Величина выборочного стандартного отклонения получается несколько больше (т. к. делят на n
–1), что обеспечивает поправку на случайность самой выборки.
В случае, когда набор данных имеет нормальное распределение, стандартное отклонение приобретает особый смысл.
На рисунке, представленном ниже, по обе стороны от среднего сделаны отметки на расстоянии одного, двух и трех стандартных отклонений соответственно.
Из рисунка видно, что примерно 66,7% (две трети) всех значений находятся в пределах одного стандартного отклонения по обе стороны от среднего значения, 95% значений окажутся в пределах двух стандартных отклонений от среднего и почти все данные (99,7%) будут находиться в пределах трех стандартных отклонений от среднего значения.
Это свойство стандартного отклонения для нормально распределенных данных называется «правилом двух третей». В некоторых ситуациях, например при анализе контроля качества продукции, часто устанавливают такие пределы, чтобы в качестве заслуживающей внимание проблемы рассматривались те результаты наблюдений (0,3%), которые отстоят от среднего на расстоянии большем, чем три стандартных отклонения. К сожалению, если данные не подчиняются нормальному распределению, то описанное выше правило применять нельзя. В настоящее время существует ограничение, называемое правилом Чебышева, которое можно применять к ассиметричным (скошенным) распределениям. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Сформировать исходные данные Совокупность СВ | В таблице 1 представлена динамика изменений дневной прибыли на бирже, зафиксированной в рабочие дни за период от 31 июля по 9 октября 1987 года. Таблица 1. Динамика изменения дневной прибыли на бирже
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Запустить Excel | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Создать файл | Щелкните на кнопке Сохранить на панели инструментов Стандартная. откройте В появившемся диалоговом окне папку Статистика и задайте имя файлу Характеристики рассеяния.xls. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Задать метку | 6. На Листе1 в ячейке A1 задайте метку Дневная прибыль, 7. а в диапазон A2:A49 введите данные из Таблицы 1. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Задать функцию СРЕДНЕЕ ЗНАЧЕНИЕ | 8. В ячейку D1 введите метку Среднее. В ячейке D2 вычислите среднее, используя статистическую функцию СРЗНАЧ. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Задать функцию СТАНДОТКЛОН | В ячейку D4 введите метку Стандартное отклонение. В ячейке D5 вычислите стандартное отклонение, используя статистическую функцию СТАНДОТКЛОН | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Уменьшите разрядность полученного результата до четвертого знака после запятой. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Интерпретация результатов | Снижение дневной прибыли в среднем составило 0,04% (значение средней дневной прибыли получилось равным –0,0004). Это означает, что средняя дневная прибыль за рассматриваемый период времени была приблизительно равна нулю, т.е. на рынке держался средний курс. Стандартное отклонение получилось равным 0,0118. Это означает, что вложенный в фондовый рынок один доллар ($1) за сутки изменялся в среднем на $0,0118, т.е. его вложение могло привести к прибыли или потере в размере $0,0118. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Проверим, соответствуют ли приведенные в Таблице 1 значения дневной прибыли правилам нормального распределения | 1. Рассчитайте интервал, соответствующий одному стандартному отклонению по обе стороны от среднего. 2. В ячейках D7, D8 и F8 задайте соответственно метки: Одно стандартное отклонение, Нижняя граница, Верхняя граница. 3. В ячейку D9 введите формулу = -0,0004 – 0,0118, а в ячейку F9 введите формулу = -0,0004 + 0,0118. 4. Получите результат с точностью до четвертого знака после запятой. |
5. Определите число значений дневной прибыли, находящихся в пределах одного стандартного отклонения. Сначала отфильтруйте данные, оставив значения дневной прибыли в интервале [-0,0121, 0,0114]. Для этого выделите любую ячейку в столбце A со значениями дневной прибыли и выполните команду:
Данные®Фильтр®Автофильтр
Откройте меню, щелкнув на стрелке в заголовке Дневная прибыль , и выберите (Условие…). В диалоговом окне Пользовательский автофильтр установите параметры как показано ниже. Щелкните на кнопке ОК.

Чтобы подсчитать число отфильтрованных данных, выделите диапазон значений дневной прибыли, щелкните правой кнопкой на свободном месте в строке состояния и в контекстном меню выберите команду Количество значений. Прочтите результат. Теперь отобразите все исходные данные, выполнив команду: Данные®Фильтр®Отобразить все и выключите автофильтр с помощью команды: Данные®Фильтр®Автофильтр.
6. Вычислите процент значений дневной прибыли, удаленных от среднего на расстоянии одного стандартного отклонения. Для этого в ячейку H8 занесите метку Процент , а в ячейке H9 запрограммируйте формулу вычисления процента и получите результат с точностью до одного знака после запятой.
7. Рассчитайте интервал значений дневной прибыли в пределах двух стандартных отклонений от среднего. В ячейках D11, D12 и F12 задайте соответственно метки: Два стандартных отклонения , Нижняя граница , Верхняя граница . В ячейки D13 и F13 введите расчетные формулы и получите результат с точностью до четвертого знака после запятой.
8. Определите число значений дневной прибыли, находящихся в пределах двух стандартных отклонений, предварительно отфильтровав данные.
9. Вычислите процент значений дневной прибыли, удаленных от среднего на расстоянии двух стандартных отклонений. Для этого в ячейку H12 занесите метку Процент , а в ячейке H13 запрограммируйте формулу вычисления процента и получите результат с точностью до одного знака после запятой.
10. Рассчитайте интервал значений дневной прибыли в пределах трех стандартных отклонений от среднего. В ячейках D15, D16 и F16 задайте соответственно метки: Три стандартных отклонения , Нижняя граница , Верхняя граница . В ячейки D17 и F17 введите расчетные формулы и получите результат с точностью до четвертого знака после запятой.
11. Определите число значений дневной прибыли, находящихся в пределах трех стандартных отклонений, предварительно отфильтровав данные. Вычислите процент значений дневной прибыли. Для этого в ячейку H16 занесите метку Процент , а в ячейке H17 запрограммируйте формулу вычисления процента и получите результат с точностью до одного знака после запятой.
13. Постройте гистограмму дневной прибыли акций на бирже и поместите ее вместе с таблицей распределения частот в области J1:S20. Покажите на гистограмме приблизительно среднее значение и интервалы, соответствующие одному, двум и трем стандартным отклонениям от среднего соответственно.